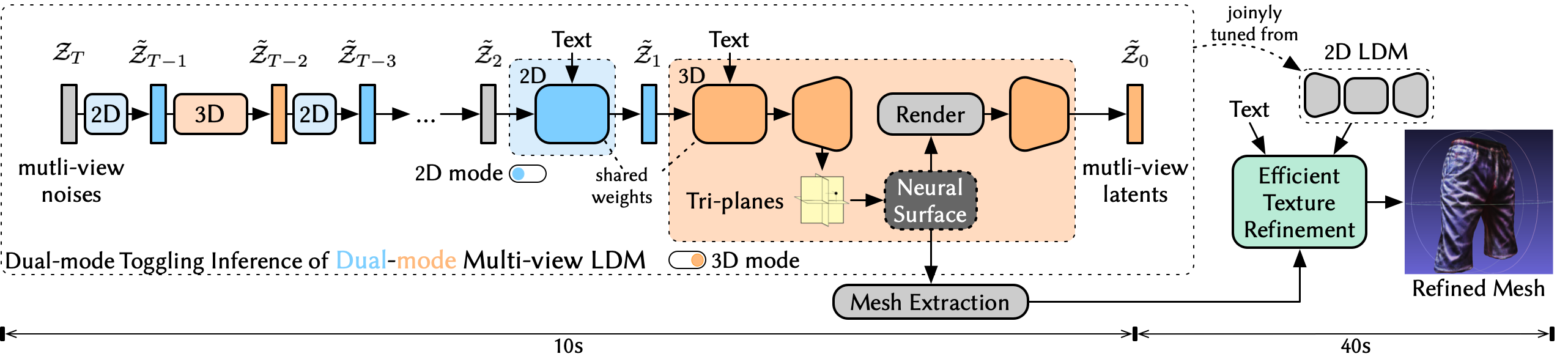
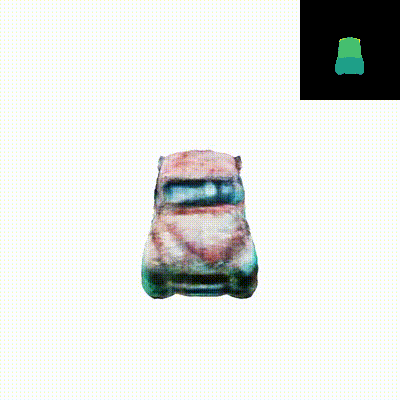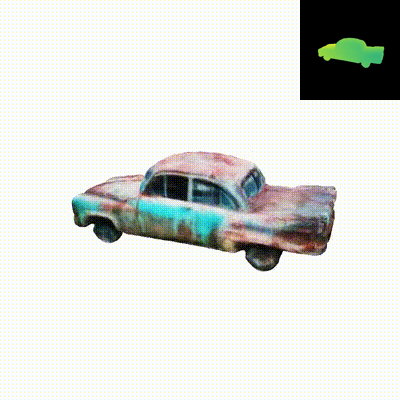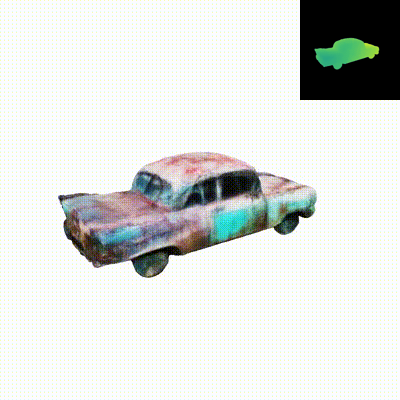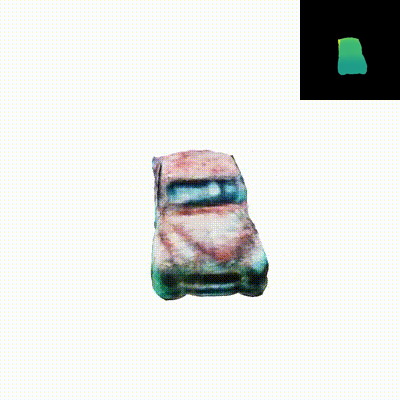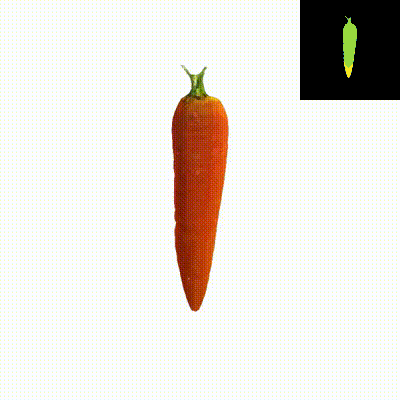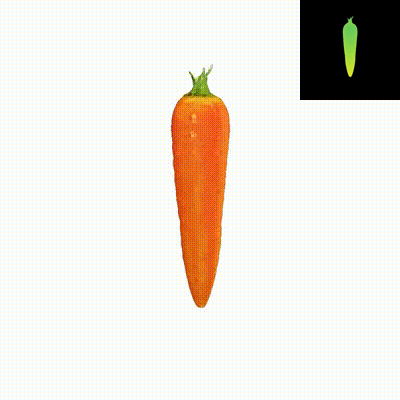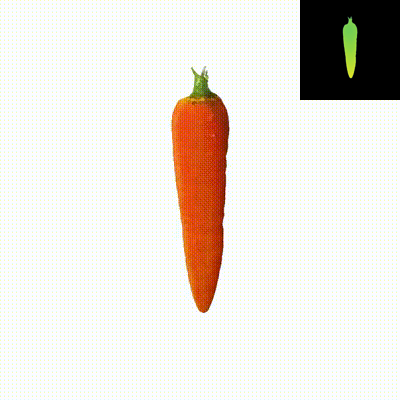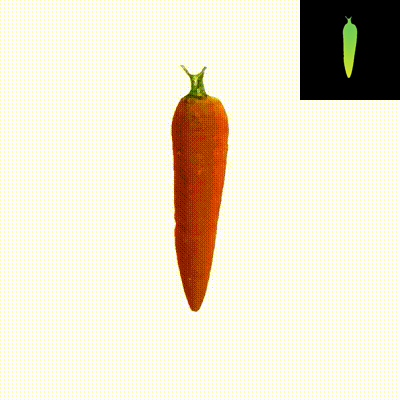We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only 1 minute. The key component is a dual-mode multi-view latent diffusion model. Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising. Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch. To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only 1/10 denoising steps with 3D mode, successfully generating a 3D asset in just 10 seconds without sacrificing quality. The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time.
 : Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion